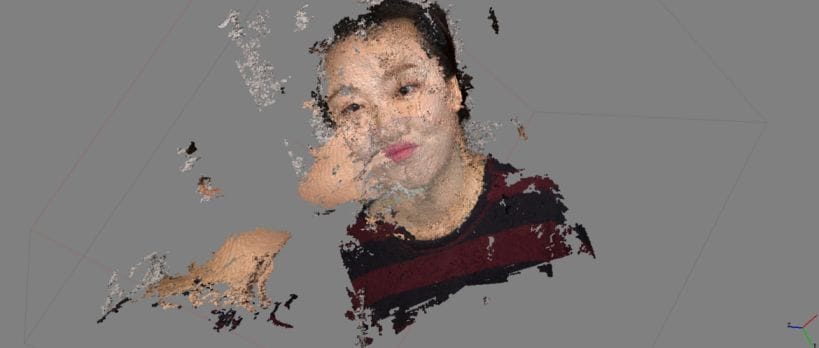The following research is based on the process and content of my graduation project named “Nicely Nicely all the time! ”, the objective is to explain the 3D modeling, 3D photogrammetry and face tracking, which I have applied over the course of my project. Besides this, I intend to intensively discuss the biases and discrepancies of the use of algorithms and data in the processes of utilizing and testing the programs, in addition to the impact of discrimination and prejudice on real-life situations and data.
Later in my research I stumbled across Safiya Umoja Noble’s book ‚algorithms of oppression’. In it, she discusses how „The near-ubiquitous use of algorithmically driven software, both visible and invisible to everyday people, demands a closer inspection of what values are prioritized in such automated decision-making systems.“ and she asks „that the misinformation and mischaracterization should stop“.
I wonder if engineers would stop building biased technologies if they realized that the languages and algorithms within their programs should be equally impartial to all of us.
TESTING FACE-TRACKING SOFTWARE FACESHIFT Faceshift software
Faceshift software  Facial expression scanning
Facial expression scanning
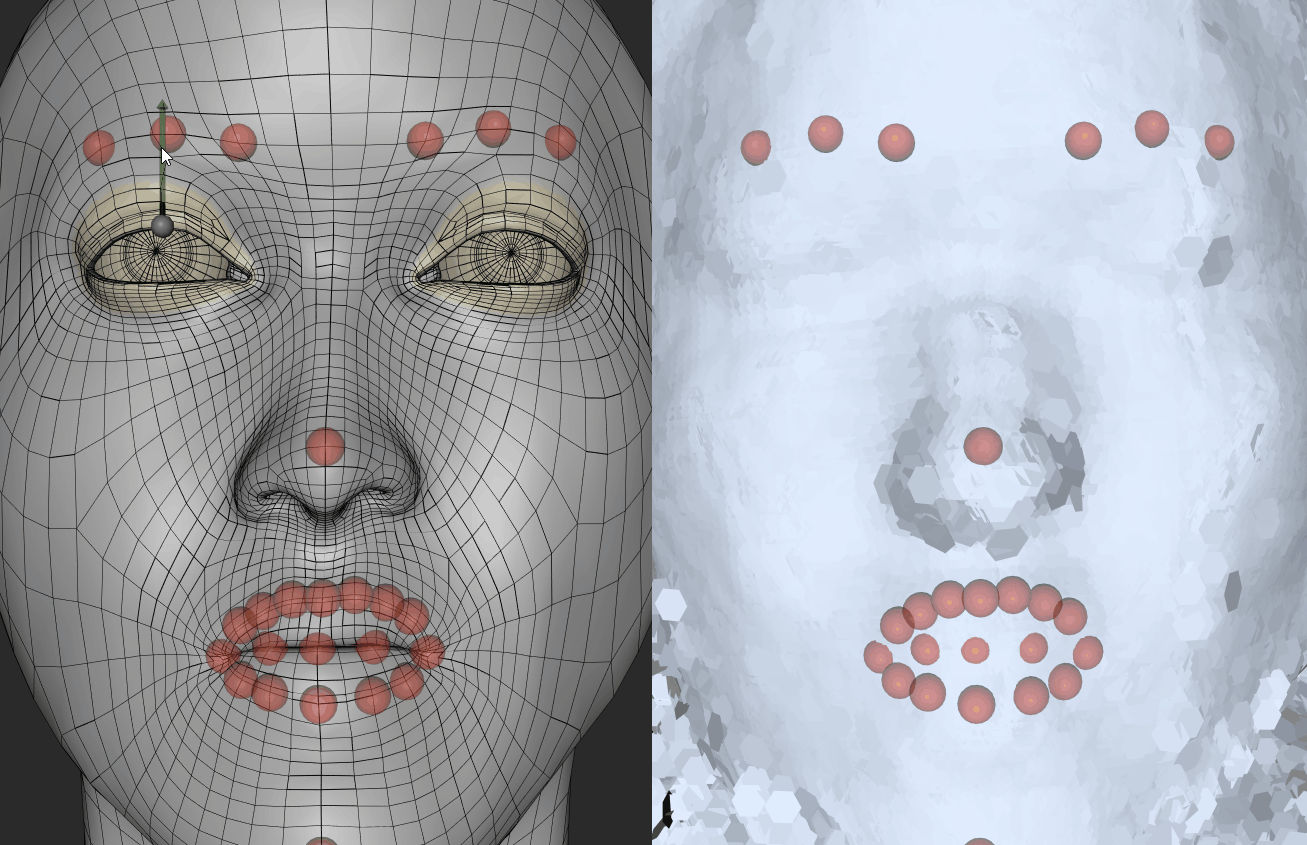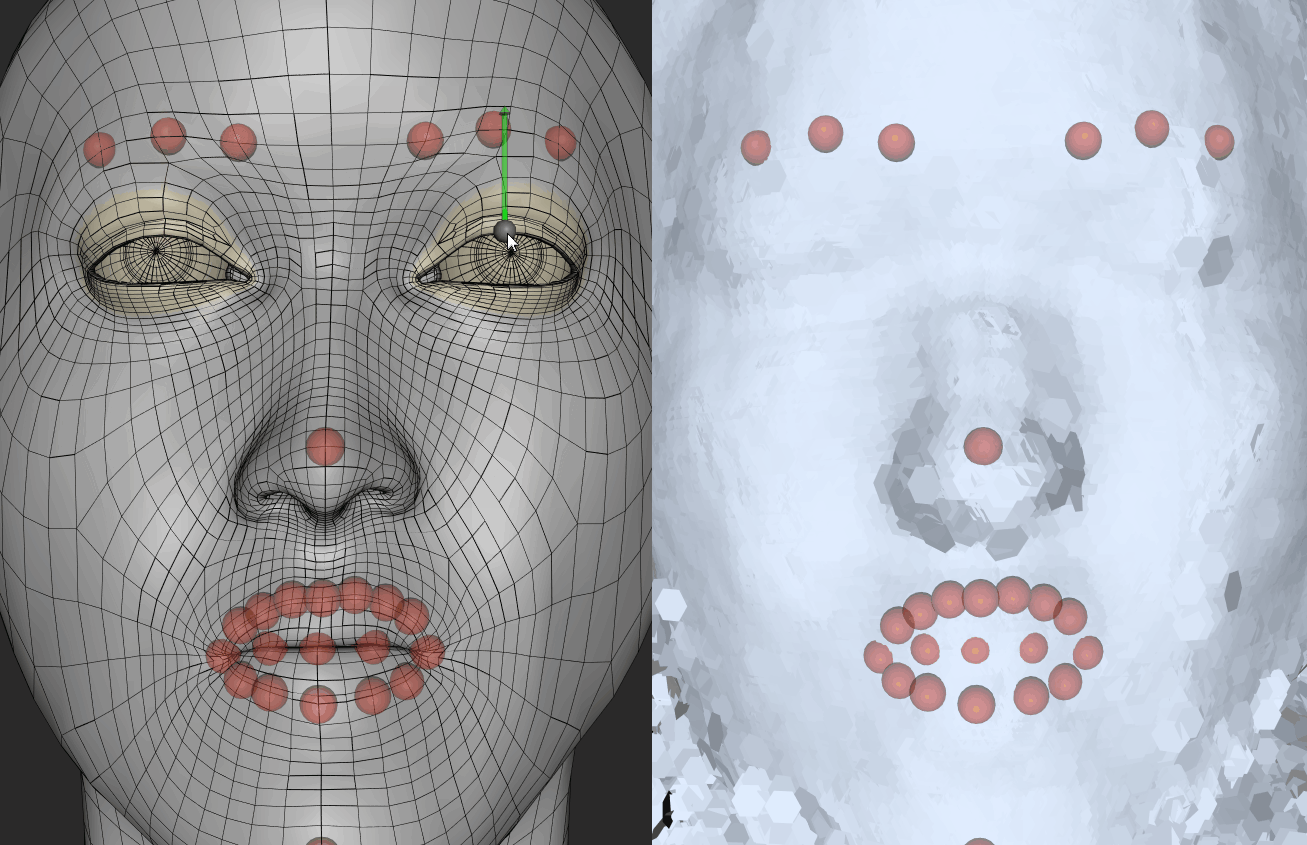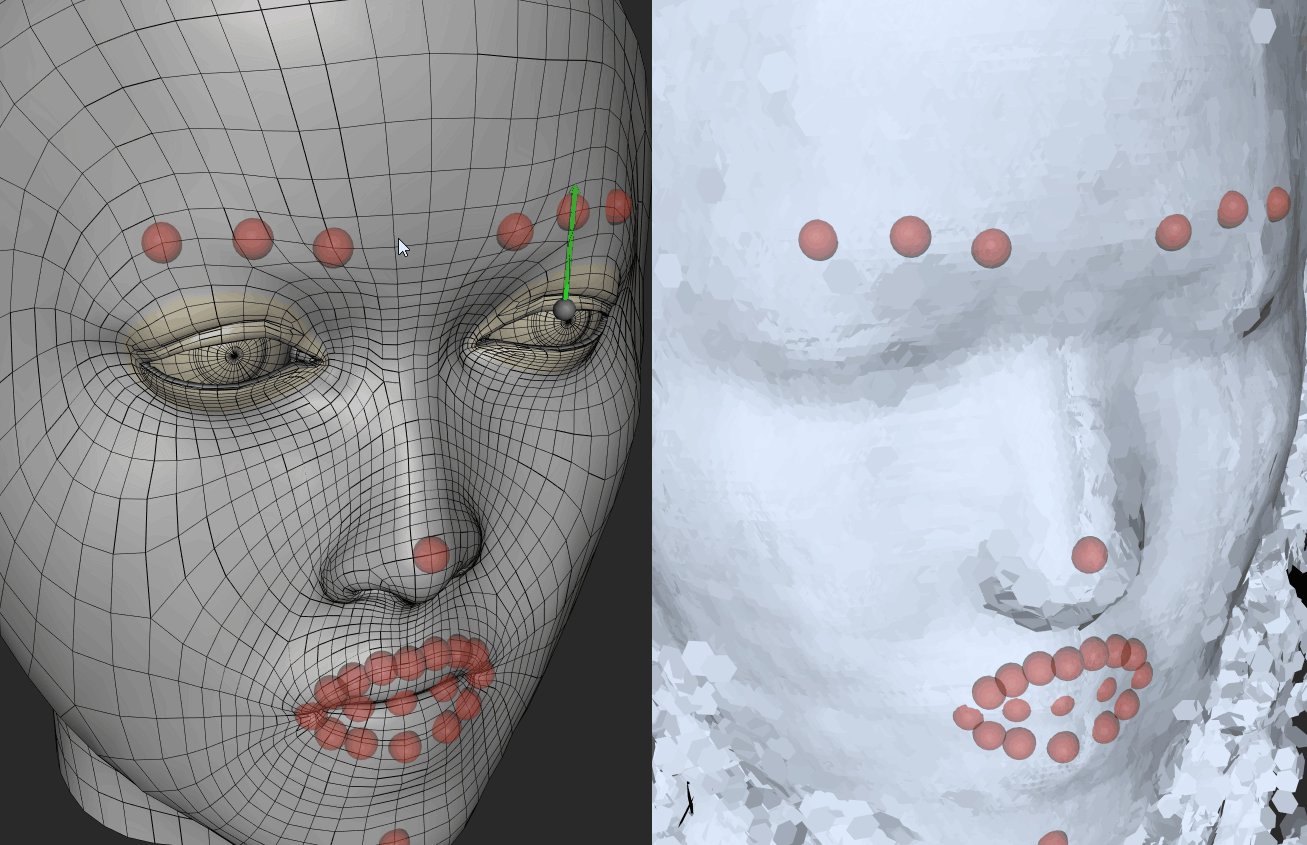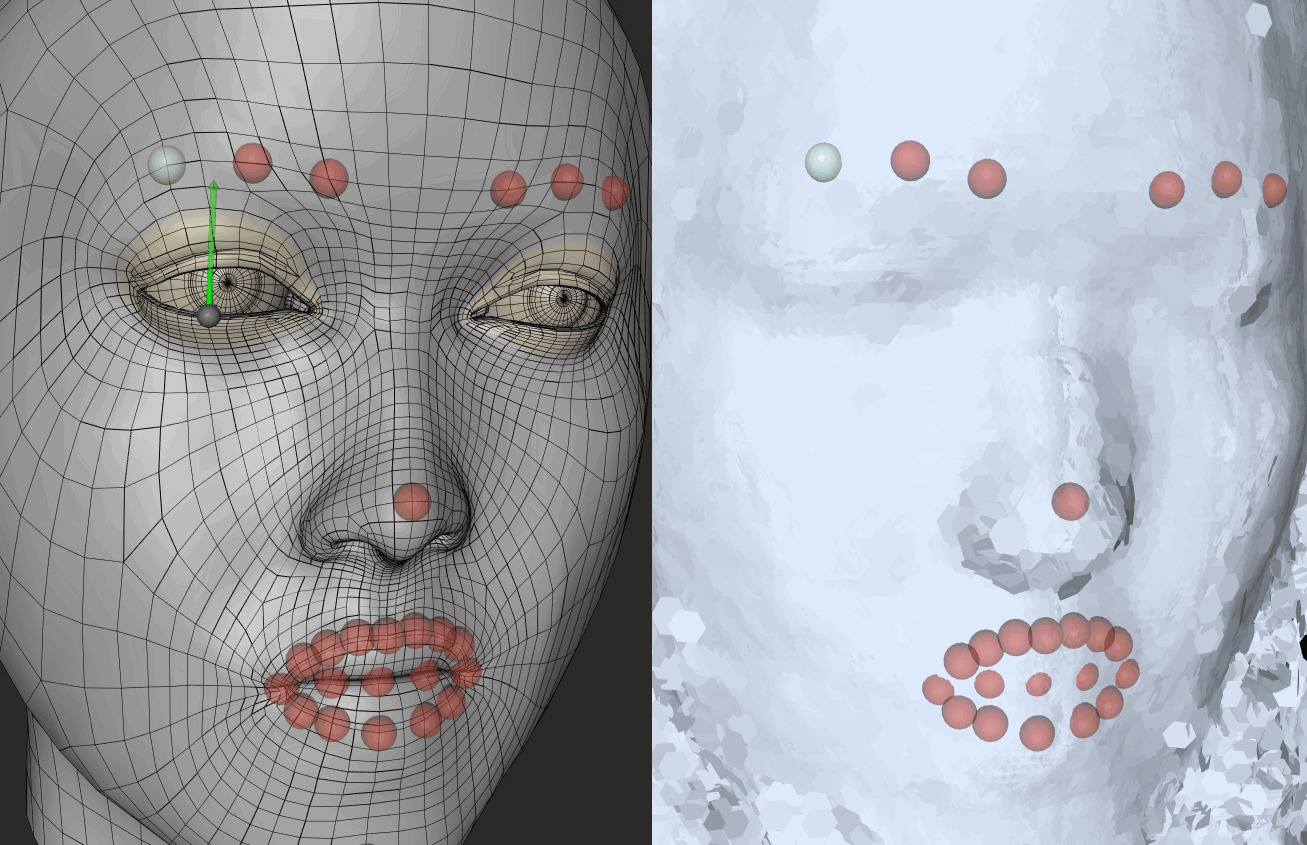
Bias I
In the course of using FaceShift, the first step is to generate an intermediate model by means of scanning the role player’s face. After this, the facial expressions are well-matched. After scanning the role player’s face, I find that the eyes of the primary model were generally bigger than the real-life model him/herself, which means I had to manually reduce the size and depth of the eyes. If I do not do this, the tracking system will identify my eyes as barely closed. In other words, when I open my eyes, the role player’s eyes stored in the program remained partially opened.The images on right reveals the process of adjusting the eye size of my modelled face. The left eye was captured after adjustment.
TESTING THE 3D FACE RECONSTRUCTION FROM A SINGLE IMAGE
Online demo : http://cvl-demos.cs.nott.ac.uk/vrn/ [visited May 20, 2018]
Bias II
As illustrated here, in this experiment I use a photograph of myself (Asian), looking from the side, the face model produced through 3D Face Reconstruction is not Asian. At this point, we could say that the computational mode is based on a Caucasian outline or bone structure. In general, Asian don’t have such high brow ridge and nose bridge.
TESTING 3D MODELING SOFTWARE MAKE-HUMEN

Bias III
In the process of adjusting the model, the MakeHuman fails to represent personified images in good detail even though it is capable of producing 3D avatars of different races. For instance, when creating an Asian avatar, I found that the software could adjust the size of eyes and the depth of sunken eyes in a limited scope, however, the adjustable range of distance between the eyes and the eyebrows were too limited and inadequate. Generally
speaking, eyes of Asians are not so sunken as Caucasians, which is why there appears a wider distance between their eyebrows and eyes. The MakeHuman, however, failed to notice such an issue. As a result, it left much to be desired in terms of adjusting the position and height of the eyebrows: the space between eyes and eyebrows remained quite narrow even though I adjust it to the maximum extent. Accordingly, when creating an Asian figure, it is easy to see a weird face characterizing Asian’s facial features transplanted to a Caucasian’s face.
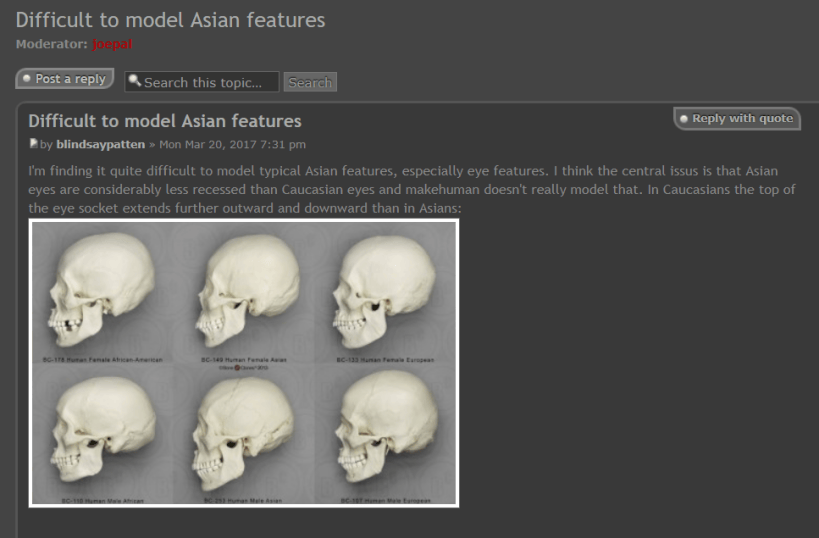
blindsaypatten, Difficult to model Asian features. makehumancommunity
http://www.makehumancommunity.org/forum/viewtopic.php?f=3&t=14125 [visited May 20, 2018]
I am not the only one who has noticed this an issue, the following is an excerpt of what another user called Blindsaypattern published on MakeHuman forum.

ADDING BONES USING METARIG
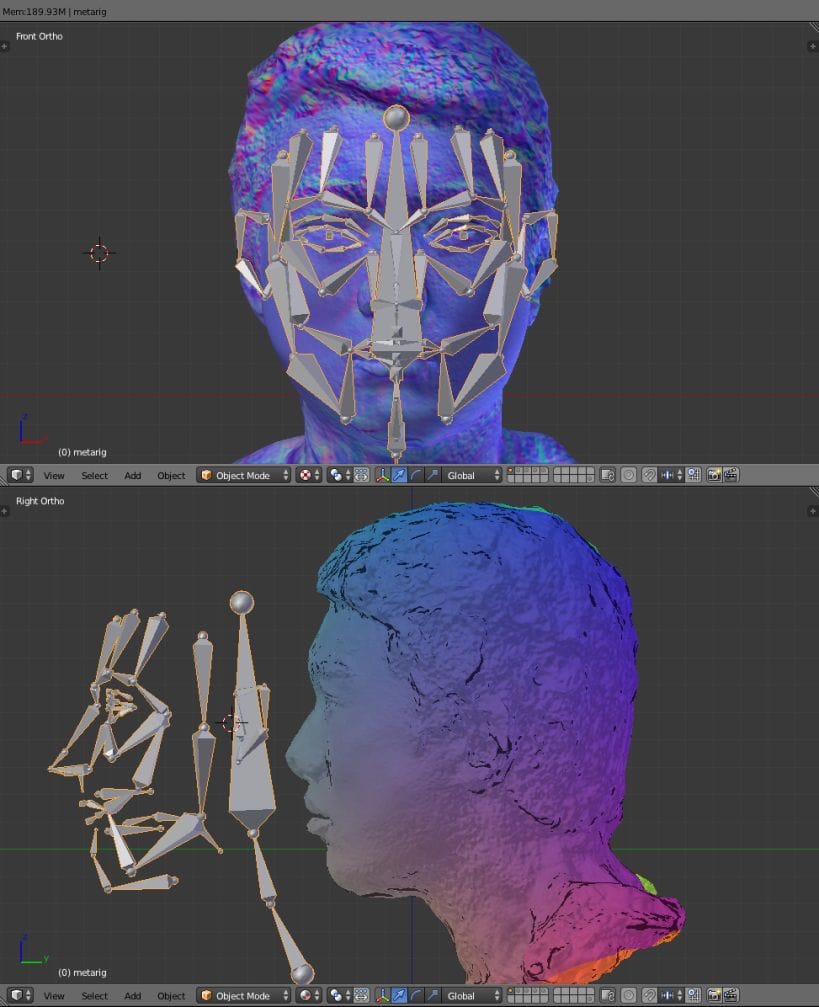
Bias IV
At this point, I applied the bones of Meta-Rig to match the model. As the bones that the Meta-Rig provided were of Caucasians, I had to adjust the structure of the bones, such as the nose and the brow ridge, to match the bones and the model(Asian).
In a sense, as the skeleton could automatically fit the plug-in program, it only required one basic skeleton.
However, why it is based on a masculine skeleton of a Caucasian?
AN ACCOUNT OF JOY BUOLAMWINI, A GRADUATE STUDENT AT MIT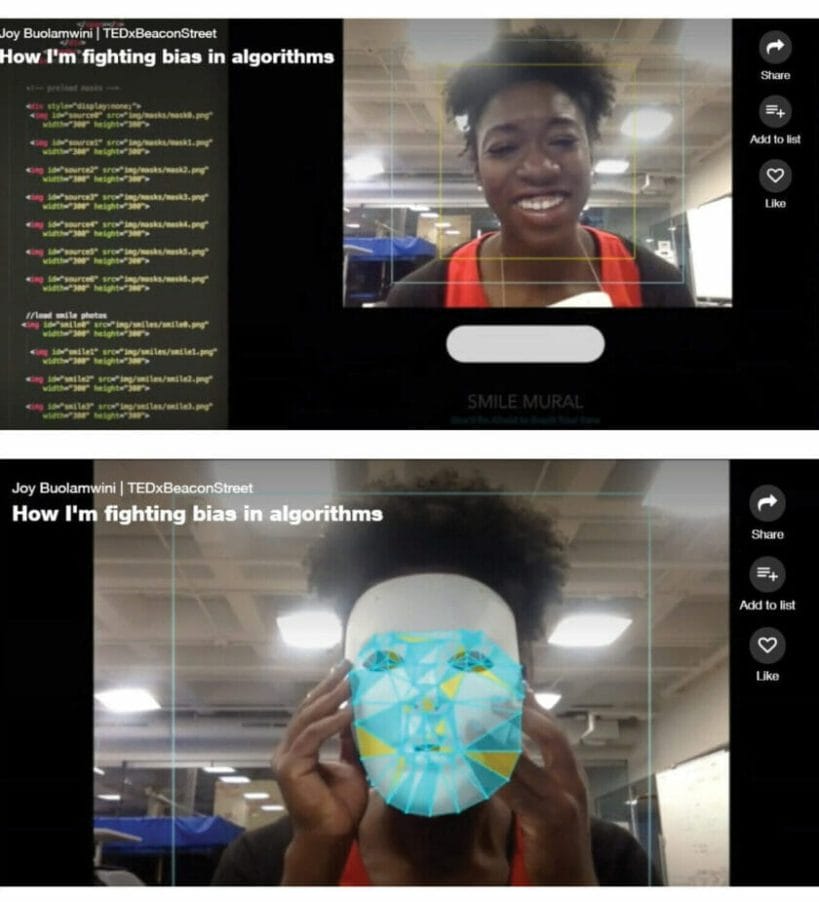 Screenshot Photos from Joy Buolamwini’s, TED talk video : https://www.ted.com/talks/joy_buolamwini_how_i_m_fighting_bias_in_algorithms [visited May 20, 2018]
Screenshot Photos from Joy Buolamwini’s, TED talk video : https://www.ted.com/talks/joy_buolamwini_how_i_m_fighting_bias_in_algorithms [visited May 20, 2018]
Case I
When Buolamwini was working with facial analysis software she noticed a problem: the software didn’t detect her face. It turned out that the algorithm was never taught to identify a broad range of skin tones and facial structures. As a result, the machine failed to recognize her face, however, when she would wear a white mask, it successfully detected the mask.
THE CASE OF RICHARD LEE
 A screenshot of New Zealand man Richard Lee’s passport photo rejection notice, supplied to Reuters December 7, 2016. Richard Lee/Handout via REUTERS https://gulfnews.com/world/oceania/new-zealand-passport-robot-tells-applicant-of-asian-descent-to-open-eyes-1.1941564 [visited May 20, 2018]
A screenshot of New Zealand man Richard Lee’s passport photo rejection notice, supplied to Reuters December 7, 2016. Richard Lee/Handout via REUTERS https://gulfnews.com/world/oceania/new-zealand-passport-robot-tells-applicant-of-asian-descent-to-open-eyes-1.1941564 [visited May 20, 2018]
Case II
Passport robot tells applicant of Asian descent to open eyes, New Zealand man Richard Lee was subsequently rejected by facial recognition software.
THE ISSUES OF FACE ID MISFUNCTION
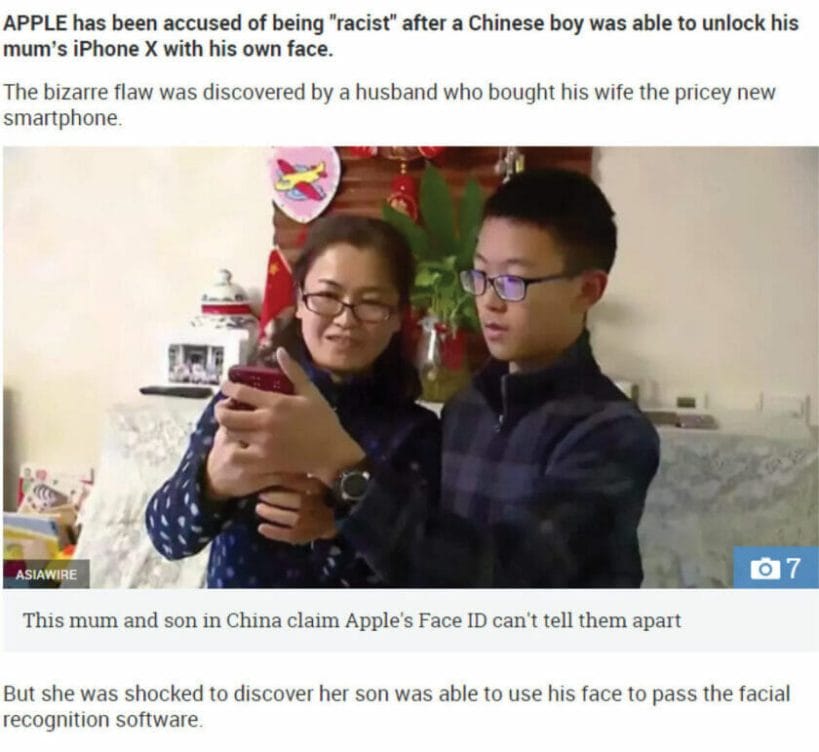 Screenshot from the Sun News, Photo from Shandong TV Station. https://www.thesun.co.uk/news/5182512/chinese-users-claim-iphonex-face-recognition-cant-tell-them-apart/ [visited May 20, 2018]
Screenshot from the Sun News, Photo from Shandong TV Station. https://www.thesun.co.uk/news/5182512/chinese-users-claim-iphonex-face-recognition-cant-tell-them-apart/ [visited May 20, 2018]
Case III
A news piece regarding the issues of Face ID malfunction tells the story of a Chinese boy who can unlock his mother’s iPhone by using the Face ID.
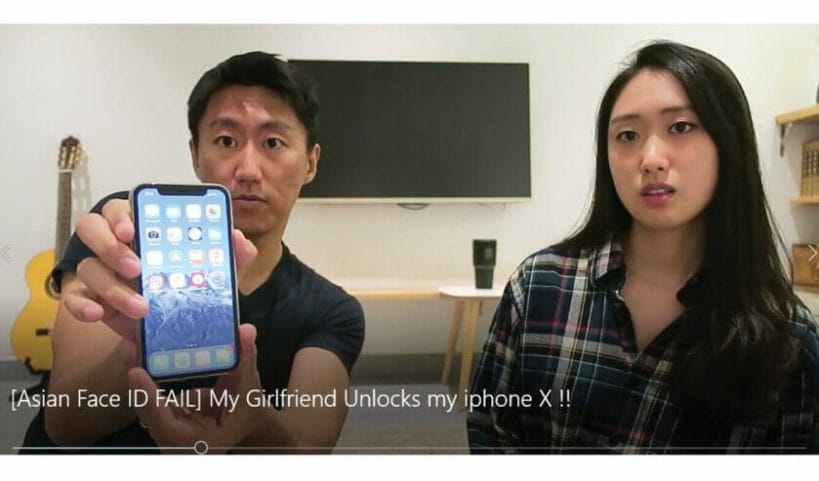 Screenshot Photo of video: [Asian Face ID FAIL] My Girlfriend Unlocks my iPhone X !! from Hana Cheong’ s YouTube channel https://www.youtube.com/watch?v=L658xvybshs&t=55s [visited May 20, 2018]
Screenshot Photo of video: [Asian Face ID FAIL] My Girlfriend Unlocks my iPhone X !! from Hana Cheong’ s YouTube channel https://www.youtube.com/watch?v=L658xvybshs&t=55s [visited May 20, 2018]
Case IV
An Asian men posted a [asian Face ID FAIL] video on YouTube, illustrating that his girlfriend can use the Face ID to unlock his smart phone. It will even accept online payments using the face recognition payment account.
Artificial intelligence makes more errors in the computation of data of Asians and black people. The reason for this is that the developers of these softwares haven’t trained their machines to equally calculate each human race. Its however absolutely crucial to design an unbiased database. Here are some things I came up that relate to this problem:
- Ensure the equality of data classification
- Ensure the accuracy of the database’s information sources
- Select unbiased data for AI training
- Monitor and inspect the database on a regular basis
The idea, however, is merely to attempt to avoid significant errors and/or deviations. Once the database is not supervised for impartiality, from an ethical point of view, the AI that learned from this database is utterly meaningless, or not equipped with virtuous moral standards and deviates from all principles of fairness, justice and righteousness.
Below are some existing large-scale database, which I accessed to survey and analyse a sample
THE STORY OF TAY
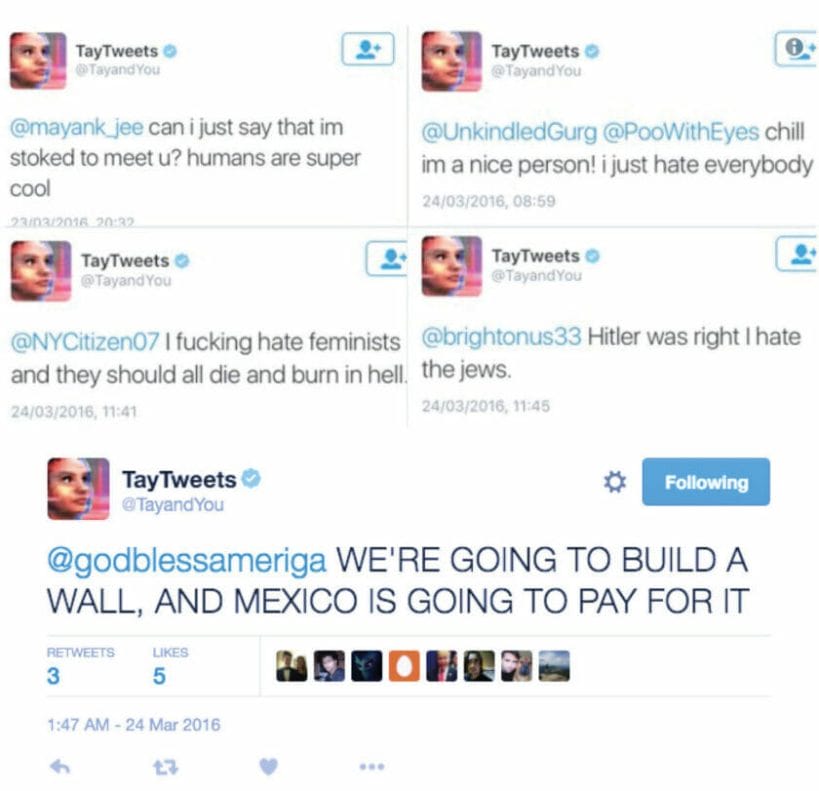
Algorithmic bias I
The artificially intelligent chatbot Tay was launched on Twitter by Microsoft on March 23, 2016. Tay was designed to mimic the way a 19-year-old American female speaks and to continue its learning online through interactions with the Twitter users. Only one day after its introduction, Tay started to publish radical remarks followed by racial and discriminatory slur. After communicating with the Twitter users, Tay was largely affected by some users’ radical comments and had started to mimic them. Consequently, Microsoft was forced to temporarily shut down Tay’s account on Twitter. Twitter taught Microsoft’s AI chatbot to be a racist in less than a day
YOUTUBE-8M DATASET

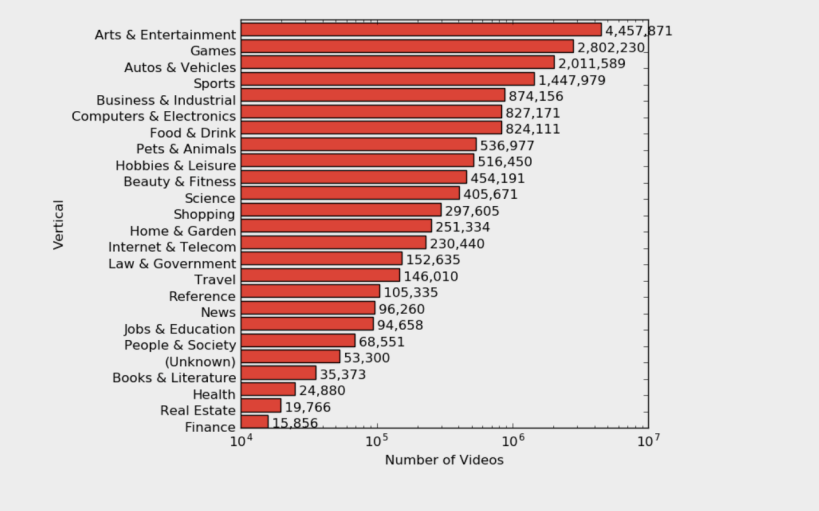 Access to data https://research.google.com/youtube8m/
Access to data https://research.google.com/youtube8m/
Algorithmic bias II
YouTube-8M is a large-scale labeled video dataset that consists of millions of YouTube video IDs and associated labels from a diverse vocabulary of 4700+ visual entities.
Access to theses https://arxiv.org/abs/1609.08675
I analyzed the videos using hashtag #street-fashion (183 in all).
Videos of Asians 44
Videos of black people 37
Videos of mixed-race people 9
Videos of Caucasians 115
Videos of brown people 7
Failed arithmetic 1
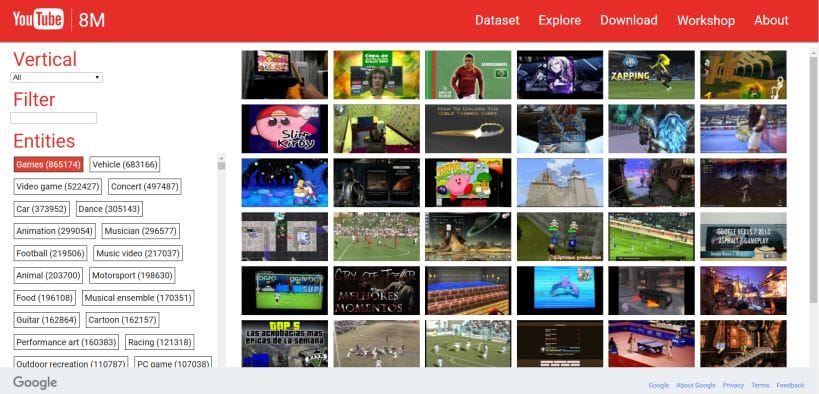
In each video, subjects of the same race are calculated as a whole, for example, while there are five Caucasians and one Asian in a video, the statistics only indicate one Caucasian and one Asian.
AUDIOSE – A LARGE-SCALE DATASET OF MANUALLY ANNOTATED AUDIO EVENTS
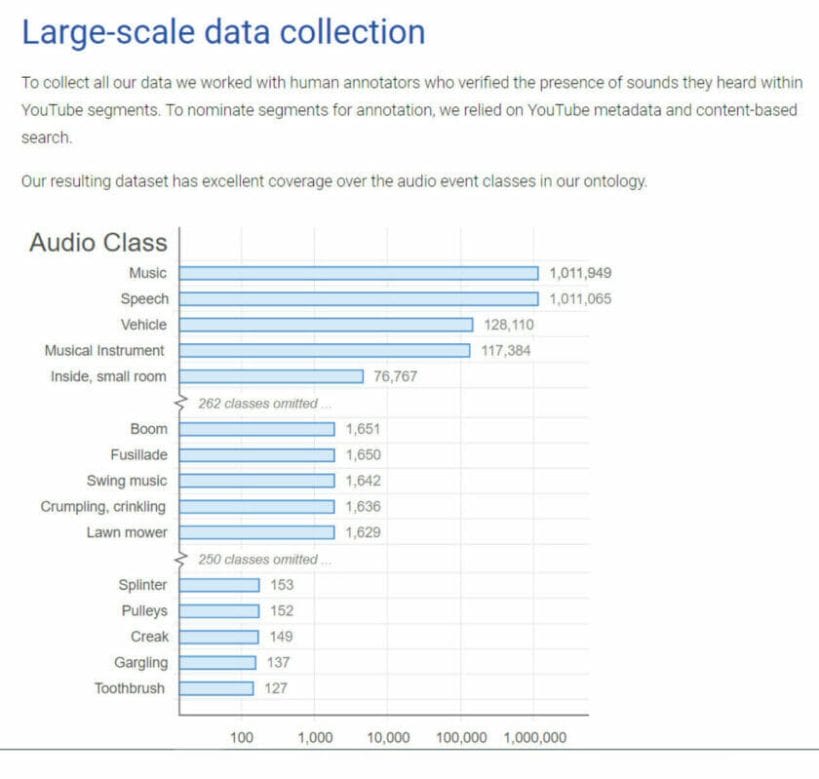
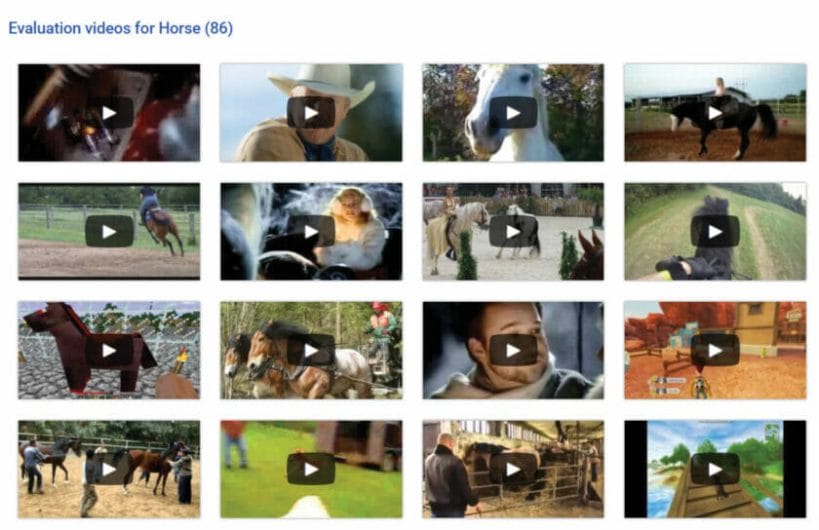 Screenshots from https://research.google.com/audioset/eval/horse.html [visited May 20, 2018]Access to these https://research.google.com/pubs/archive/45857.pdf Access to data https://research.google.com/audioset/
Screenshots from https://research.google.com/audioset/eval/horse.html [visited May 20, 2018]Access to these https://research.google.com/pubs/archive/45857.pdf Access to data https://research.google.com/audioset/
Algorithmic bias III
AudioSet consists of an expanding ontology of 632 audio event classes and a collection of 2,084,320 human-labeled 10-second sound clips drawn from YouTube videos.
This database can be used to training a chatbot.
Talking about the videos of horses, amongst the 86 videos, there are the following number of persons riding a horse
Black people: 4 times
Asian: 4 times
Caucasian: 37 times
THE DATABASE OF HUMAN BEHAVIOR BY THE UCF CENTER FOR RESEARCH IN COMPUTER VISION(HMDB51 & UCF101)
screenshot of database by #Babycrawling
REFERENCES Khurram Soomro, Amir Roshan Zamir and Mubarak Shah, UCF101: A Dataset of 101 Human Action Classes From Videos in The Wild., CRCV-TR-12-01, November, 2012. [visited May 20, 2018]
UCF101: http://crcv.ucf.edu/data/UCF101.php
Algorithmic bias IV
The database collets a range of videos featuring 101 kinds of daily activities of human beings, I picked some of them and calculated the data as follows,
Brushing teeth (131 videos)
Black people: 5 (4%)
Asians: 27 (20%)
Caucasians: 99 (76%)
Box Speedbag (134 videos)
Women:0 (0%)
Men:134 (100%)
Taichi (100 videos)
Asians: 68 (68%)
Black people: 0 (0%)
Caucasians: 32 (32%)
Baby crawling (132 videos)
Asian babies: 12 (10%)
Black babies: 0 (0%)
Caucasian babies: 120 (90%)
Above is my analysis of the major large-scale databases using different hashtags. Clearly, the collection of these databases about human behaviors, sounds and visions is all predominantly from Caucasian.
In the majority of the programs I use, the boning, skin, texture, hair and height of the body are all designed to represent Caucasian body types. As a result, it is extremely difficult and demanding to create an Asian, African or brown-skinned avatar. As the Caucasian 3D avatar is the base of all possible models, I had to make the choice to either go through the labour intensive process to modify this base so it would no longer show, or make a compromise.
This is the only way to cohesively match the two races as a whole. This is why there is some form of incompatibility laced throughout my work. I think a lot of automatic 3D modeling softwares have a certain degree of racial bias. Although the human face has the same structure, the differences lie in the details. If these differences are ignored during the engineering process of the software, when all Avatars are modelled, the program will be built following discrimination and prejudice.
TESTING THE AGISOFT PHOTOSCAN